
Containers, systemd-nspawn and overlayfs
This is a little blurb about how to use namespaces most efficiently at the time of writting. In particular, systemd-nspawn offers a lot of flexibility, is lightweight, and takes advantage of having the host and guest running systemd. As much as I dislike systemd’s design in some ways, this is very practical in this case.
A quick introduction
What’s a container?
Namespaces are generally called “containers” outside the kernel world. Really, a container is a userspace process running in a set of namespaces. The most typical example is to run init (the first Linux process when you boot) or an init alternative inside the namespace, and chroot 1 it.
This makes the container look like a fresh/separate operating system, a little bit like a virtual machine would - except all resources (memory, disk, kernel, etc.) are seen and shared by the host.
What’s a namespace really?
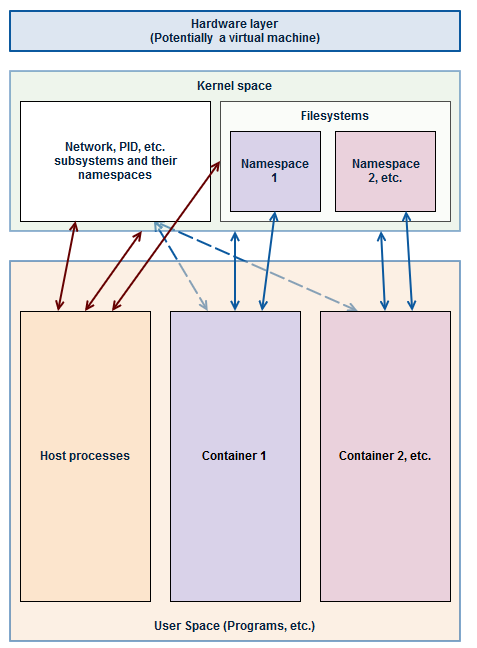
Linux namespaces are not new. They’re the kernel-side that allow to separate resources at the process, filesystem, network, user, etc level from within the same kernel.
Implementation started several years ago, and has become useable more recently around the Linux kernel 3.6+ series. This has been done by implementing a new creds structure in the kernel, that holds information on the current namespace and permissions of an object. If you’re interested, full details are at kernel.org (this is a good read!).
Available namespaces
A container does not necessarily enable all namespaces, however most do to achieve more thorough separation of resources.
| Namespace | Description |
|---|---|
| File system | Different view of the filesystem. Generally provided by a chroot of a different mount point. Contains often see/write the host or each other’s filesystem namespaces due to bind mounts (such as /proc, /sys, and /dev) |
| PID | Different view of the process table. Additionally, you can’t send signals from one PID namespace to another. Containers can’t see/write the host or each other’s PID namespaces. |
| IPC | Different view of the shared memory, messages, semaphores. Containers can’t see/write the host or each other’s IPC namespaces. |
| Network | Different view of the network interfaces, netfilter, routes, etc. Containers can’t see/write the host or each other’s firewall, IPs, etc. |
| UTS | Different view of the system hostname. Containers can’t see/write the host or each other’s hostname. |
A visual representation of the filesystem namespace
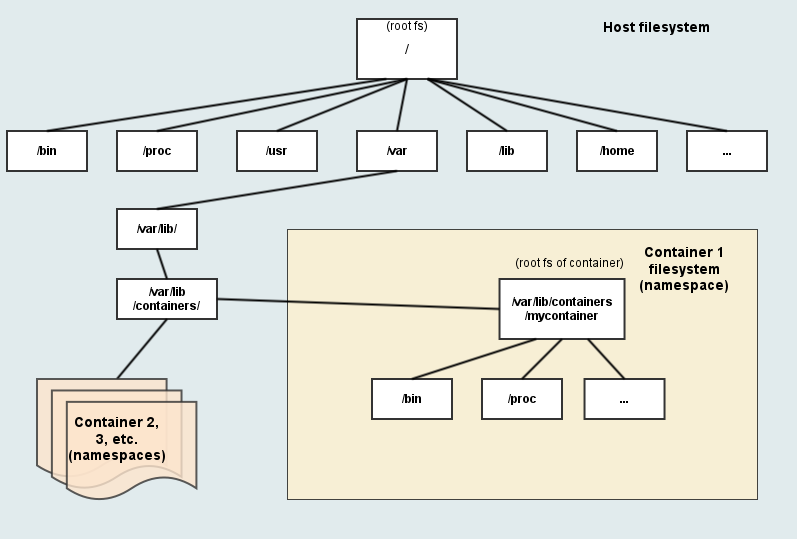
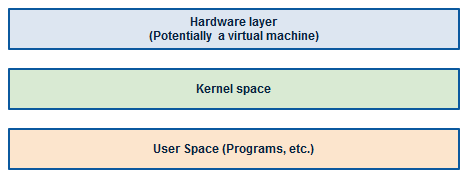
Visual representations of host vs guests
Regular Linux system (host)
Container inside the host (guest)
Systemd, docker, LXC, etc.
While there’s plenty of software using namespaces, I’ll just drop some notes about the most notable ones:
Docker
Docker is a well-known, dare I say, celebrity in the container world.
Written in Go - it provides - an API with a root daemon - the Docker file format to create images - a large image repository - some utilities - the ability to deploy someone elses setup with one command
Cons - Poor image repository security - you don’t know what you run (being worked on) - Poor container isolation (being worked on) - Hard to debug - Always running, mandatory root daemon (by design)
LXC
LXC has been around for a while, and is seen as a qemu/VM 2 replacement. More recently, it has been rewritten in C.
Cons - Slightly complex to use - Poor reputation - Most setups can be escaped from by default by root users in guests - Cannot easily create or import images
OpenVZ
OpenVZ (now “OpenVZ Virtuozzo”) has also been around for a long time and greatly participated to Linux namespaces popularity, including a large part of the kernel namespacing code itself.
Pros - Large documentation - Supports live migration of images - Plenty of features - Commercial support
Cons - Heavy, complex - Some features are commercial-only (proprietary)
systemd-nspawn
The most recent, nspawn is a part of systemd - the init system. Being part of the init system gives it specific advantages such as being able to coordinate all system logs, automatically masquerade the host network, and so on.
Pros - Fast, simple CLI commands - No additional daemons - Compatible with most image formats - Can pull images directly from Docker’s repository (“one command image setup”) - Supports cgroups and seccomp via systemd directly (single place to setup) - Flexible
Cons - No API - Systemd guest required for using all features
Using your own containers with systemd-nspawn + overlayfs
This how-to will use in particular:
- Arch Linux host (lightweight but not as limited as CoreOS)
- systemd-nspawn
- overlayfs as root filesystem for guests
OverlayFS allows guests to share their filesystem cache and works as a COW 3 filesystem from a base image. This ensure higher performance and low memory/disk usage.
Prerequisites
- Have ArchLinux installed
- Understand that all containers will be stored at
/var/lib/container/;-) - Have /var/lib/container as an ext4 filesystem (or part of an ext4 filesystem)
- That’s it.
:
Setup your own base system “image”
Dependencies
Ensure you have arch install scripts installed:
$ sudo pacman -S arch-install-scripts
Setup
We’re going to create the base image as /var/lib/container/default-ns-1.
While I’m calling this an image, it really just is a filesystem directory - this is so that the filesystem cache can be most efficient. Any image file can be mounted and copied to convert it to the native filesystem.
$ sudo -s
# You are now root
$ pacstrap -i -c -d /var/lib/container/default-ns-1 base vim sudo
$ cp /var/lib/container/default-ns-1
$ cp /etc/os-release etc/os-release
$ arch-chroot .
# You are now in a chroot of the base image
# Needed to be able to login locally
$ rm -f /etc/securetty
# Replace "kang" by a user you'd like to have by default on all images
$ useradd -m -g wheel kang
$ echo "en_US.UTF-8 UTF-8" >> /etc/locale.gen
$ locale-gen
$ ln -s /usr/share/timezone/UTC /etc/localtime
$ ln -s /run/systemd/resolve/resolv.conf /etc/resolv.conf
$ systemctl enable systemd-resolved
$ pacman -Suy
# If you want automatic networking setup:
$ systemctl enable systemd-networkd
# Finally, leave the chroot
$ exit
Ok, your base image is now setup. You can modify things in it at any time - changes will go to all “child” images.
Create your first child “image”
Creation
A child image is simply an overlay on top of the base image. It uses no disk space until you start using it and writing files. The child image only store differences with the base image.
You can make as many child images as you want. We’ll make a child image to run apache in this example.
$ cd /var/lib/container
$ mkdir child_apache child_apache_work child_apache_up
$ sudo modprobe overlayfs
$ sudo mount -t overlay overlay -o lowerdir=/var/lib/container/default-ns-1,upperdir=/var/lib/container/child_apache_up,workdir=/var/lib/container/child_apache_work /var/lib/container/child_apache
At this point, if you list /var/lib/container/child_apache it should have the same contents as /var/lib/container/default-ns-1.
Mount at boot
In order to mount it at every boot you can add it to /etc/fstab:
overlay /var/lib/container/child_apache overlay noauto,x-systemd.automount,lowerdir=/var/lib/container/default-ns-1,upperdir=/var/lib/container/child_apache_up,workdir=/var/lib/container/child_apache_work 0 0
noauto,x-systemd.automount ensure that systemd will not block in case something goes wrong during the mount at boot. Also, it will only mount the child image automatically when the container is started - otherwise, the image will stay unmounted.
You will need to reboot or restart systemd’s mount service for the fstab entries to be taken into account.
Start the container
Manual startup
You can simply start it via nspawn directly (ensure you have mounted the overlayfs already):
$ sudo systemd-nspawn --boot -j -M child_apache
[...] plenty of boot messages [...]
Login:
When exiting, the container will still be running. It can be turned off via:
$ sudo machinectl poweroff child_apache
Automatic start at boot
$ sudo systemctl enable systemd-nspawn@child_apache.service
That’s it!
Networking notes
Ensure that you’re using systemd-networkd host-side for networking if you would like to make use all systemd’s easy networking setup guest-side.
The default for systemd-nspawn is to setup an automatic veth network. If you would not like that, and prefer to disable the network namespace, you can edit the service file:
$ cp /usr/lib/systemd/system/systemd-nspawn@.service /etc/systemd/system
$ vim /etc/systemd/system/systemd-nspawn@.service
Simple remove the argument “–network-veth” from the systemd-nspawn command to disable automatic networking and network namespacing. Your guest will share the network with the host in this case. You will need to disable and re-enable any container you have already enable with systemctl to take the changes into account.
System updates and base image changes
For system updates, we’ll take advantage of overlayfs’ exposing the filesystem differences between the base image and the child images.
Update base image
First, just update the image…
$ sudo arch-chroot /var/lib/container/default-ns-1 pacman -Suy
Then, ensure the child does not have any identical file that is more recent, else, delete them (force the child to use the base image’s version).
Attention, Child’s version will be lost!
Remount the childs
$ sudo mount -oremount /var/lib/container/child_apache
Restart the childs
If you want to ensure that all changes are taken into account, you may need to restart services on the child, or reboot it entierely (which is probably just as fast since it’s containers):
$ sudo machinectl reboot child_apache
That’s it!
Comments